Practical Full Resolution Learned Lossless Image Compression
Citation
@INPROCEEDINGS{8954418, author={F. {Mentzer} and E. {Agustsson} and M. {Tschannen} and R. {Timofte} and L. {Van Gool}}, booktitle={2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, title={Practical Full Resolution Learned Lossless Image Compression}, year={2019}, volume={}, number={}, pages={10621-10630},}
どんなもの?
画像の可逆圧縮。画像から RGB 値それぞれの確率分布を学習して、 adaptive arithmetic coding(要調査。 H.264 で使われている符号化法?)で符号化
先行研究と比べてどこがすごい?
- 先行研究として可逆圧縮は、機械学習を用いるものは挙げられていない(非可逆圧縮はいろいろある)
- 画像の確率分布を学習するモデルとして PixelCNN が挙げられているが、このモデルから画像を生成しようとすると、各ピクセルごとに計算が必要(しかも前のピクセルに依存するので並列化できない)で非常に遅い
そこで、非機械学習の可逆圧縮手法(PNG, JPEG2000, WebP, FILF)と遜色ない速さで、エンコード・デコードできるような、画像の確率分布モデルを作った。あるピクセルの値を得るのに、前のピクセルの値に依存しない形にすることで高速化を狙う。
技術や手法のキモはどこ?
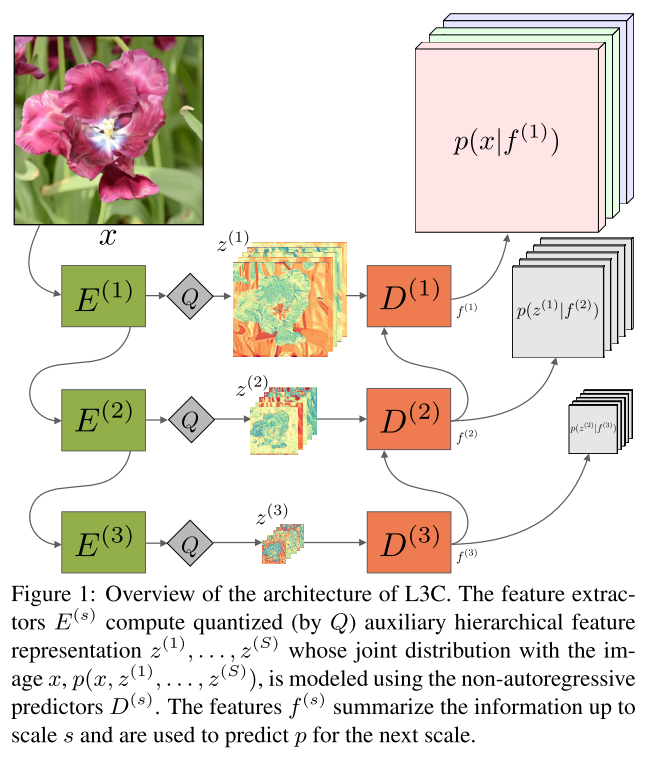
サブピクセルの自己回帰(1個前のピクセルの情報から自身のピクセルを予測する)ではなく、階層的な補助特徴量を導入した。
E, D が畳み込みニューラルネットワークになっており、特徴量抽出では、大きいサイズで得られた特徴を使って、小さいサイズの画像を生成する。予測器(D)は、その逆をやる。
損失関数は、入力画像と予測器出力の交差エントロピー。
どうやって有効だと検証した?
速さについて
PixelCNN とその高速化版 Multiscale-PixelCNN を使って、確率分布を学習し、確率分布から画像をサンプリングする速度を比較。桁が違う。
圧縮率について
PNG, JPEG2000, WebP, FILF と比較。 FILF には負けた。
議論はある?
いろんな画像のデータセットではなく、もっとドメインを絞った応用も考えられる。
次に読むべき論文は?
- 非機械学習で最強の可逆圧縮形式: FLIF: Free lossless image format based on MANIAC compression
- Lossy Compression の例いくつか読むべきだよな