Conditional Probability Models for Deep Image Compression
Citation
@INPROCEEDINGS{8578560, author={F. {Mentzer} and E. {Agustsson} and M. {Tschannen} and R. {Timofte} and L. V. {Gool}}, booktitle={2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition}, title={Conditional Probability Models for Deep Image Compression}, year={2018}, volume={}, number={}, pages={4394-4402},}
どんなもの?
画像の非可逆圧縮。オートエンコーダ + Importance Map。
先行研究と比べてどこがすごい?
- 標準的な CNN を使って実装出来て、シンプル
- PixelRNN ベースなので全ピクセルを順番に処理しなければいけないが、符号割り当てごとに並列化できる
技術や手法のキモはどこ?
- Importance Map
- 潜在空間の値を K 層に分けてることで、画像の似た部分に同じ符号を割り当てるように学習を進めるのを補助する
- エンコーダ、デコーダ、量子化器の学習と、ピクセルの確率分布の学習のふたつを、並行して学習する
どうやって有効だと検証した?
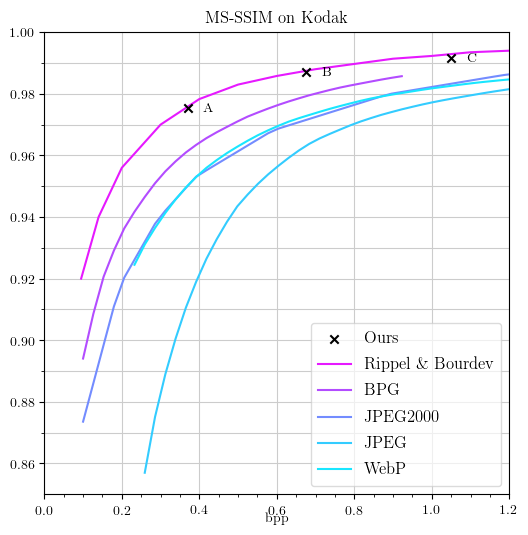
比較対象は、オートエンコーダと RNN のもの。

これを読んで知りたかったこと
離散値に量子化するのを学習ってどうやるの?
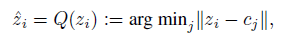 を
を 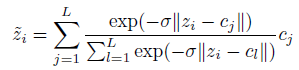 で表す。
で表す。
z は潜在空間ベクトル、 L は符号数、 c は符号に対応する(潜在空間ベクトルを実数値にしたときの)値。
ということは? → 差が大きいほど、負の指数関数は小さくなるから、一番差が小さい j のときの cj の値に近似した値が出力される?
TensorFlow では次のように表せる。
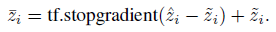
次に読むべき論文は?
- Importance Map を導入した手法: Learning Convolutional Networks for Content-weighted Image Compression